이번 글을 통해서는 데이터베이스 테이블의 Primary Index와 Secondary Index에 대해서 알아보겠습니다.
Primary Index
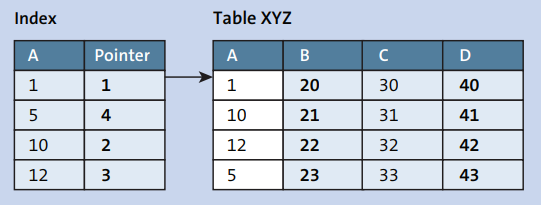
데이터베이스 테이블의 키 필드들은 테이블의 Primary Index를 형성합니다. 데이터베이스 테이블이 생성될 때, 시스템은 자동으로 키 필드에 대한 Primary Index를 생성합니다. 인덱스는 실제 테이블의 복사본으로 생각할 수 있으며, 필드 수를 줄인 형태로 구성되며 (인덱스 필드만 포함), 테이블의 다른 필드를 가리키는 포인터를 가지고 있습니다. 인덱스의 항목은 항상 정렬되어 테이블 레코드에 더 빠른 액세스를 제공합니다. 인덱스 필드를 사용하여 테이블 레코드를 검색할 때, 시스템은 데이터를 빠르게 검색하기 위해 데이터베이스 테이블을 수동으로 스캔하는 대신 인덱스를 확인합니다.
예를 들어, 테이블 XYZ에는 A, B, C 및 D라는 네 개의 필드가 있으며, A가 주요 필드인 경우를 가정해 봅시다. 만약 SELECT * FROM TABLE xyz WHERE A = '10'와 같은 select 쿼리를 작성한다면, 시스템은 A=10인 항목을 찾기 위해 인덱스를 확인하고 테이블로부터 해당 행의 나머지 필드를 가리키는 포인터를 사용하여 데이터를 검색합니다 (아래 그림 참조).
Secondary Index
기본적으로 생성되는 Primary Index 외에도, Secondary Index라고 하는 다른 인덱스를 생성할 수 있습니다. 이러한 인덱스는 WHERE 절에서 완전한 Primary Key가 사용되지 않는 테이블에서 조회를 수행해야 할 경우에 필요합니다. 예를 들어, D=41인 경우에 테이블 XYZ를 검색하는 경우, 시스템은 Primary Index를 사용할 수 없습니다. 왜냐하면 Primary Index는 주요 필드만 저장하기 때문입니다.
적절한 인덱스가 없는 경우 시스템은 전체 테이블 스캔을 수행하며, 이는 성능에 영향을 미칩니다. WHERE 절에서 완전한 Primary Key를 제공할 수 없는 경우 전체 테이블 스캔을 피하기 위해 Secondary Index를 생성할 수 있습니다.
데이터베이스 커널은 SQL Optimizer(옵티마이저)로 구성되어 있습니다. SQL Optimizer(옵티마이저)는 SQL 쿼리를 분석하고 비용 결정(Cost Determination)과 테이블 통계(Table statistics)를 분석하여 데이터에 대한 액세스를 최적화합니다. SQL 옵티마이저는 데이터에 액세스하기 위한 가장 적합한 검색 전략을 선택합니다. 예를 들어, 테이블에 여러 인덱스가 있는 경우, SQL 옵티마이저는 자동으로 데이터를 읽기 위해 가장 적합한 인덱스를 선택합니다. SQL Optimizer(옵티마이저)는 또한 가능한 인덱스 중 어느 것을 선택하는 것보다 전체 테이블 스캔이 더 효율적인 액세스를 제공하는지 여부를 결정할 수도 있습니다.
때로는 적합한 인덱스가 있는 상황에서도 SQL Optimizer(옵티마이저)가 인덱스를 무시하고 전체 테이블 스캔을 수행할 수 있습니다. 이는 SQL Optimizer(옵티마이저)가 프로파일 설정으로 인해 전체 테이블 스캔의 비용이 Secondary Index 사용 비용보다 낮다고 판단하는 경우에 발생할 수 있습니다. Oracle과 같은 특정 데이터베이스는 힌트(hint)를 지원하여 응용 프로그램 개발자로서 일반적으로 SQL Optimizer(옵티마이저)가 수행하는 결정을 직접 내릴 수 있게 합니다.
개발자가 SQL 옵티마이저가 알지 못하는 데이터에 대한 정보를 알고 있을 수도 있습니다. 예를 들어, 특정 쿼리에 대해 특정 인덱스가 더 선택적이라는 것을 알고 있을 수 있지만, SQL 옵티마이저는 이를 무시할 수 있습니다. 이러한 경우에는 힌트(hint)를 사용하여 SQL 옵티마이저가 특정 인덱스를 사용하도록 강제할 수 있습니다. 쿼리에 힌트를 제공하기 위해 %_HINTS 매개변수를 사용할 수 있습니다.
SELECT <fields> INTO TABLE<itab> FROM <database table>
WHERE <logical expression>
AND <logical expression>
%_HINTS <database name> 'INDEX("<database table>" "Index name")'.위 예시에서 %_HINTS구믄의 Paraeter 뒤에는 데이터베이스 이름과 사용해야 할 테이블의 인덱스가 따라옵니다. 데이터베이스가 Oracle이고 SQL 옵티마이저에게 SPFLI 테이블의 Secondary Index SPFLI~001을 사용하도록 하려면 아래 에 나와 있는 대로 쿼리를 작성할 수 있습니다
SELECT * FROM spfli
INTO TABLE it_spfli
WHERE cityfrom EQ ' NEW YORK'
AND cityto EQ ' SAN FRANCISCO'
%_HINTS ORACLE 'INDEX("SPFLI" "SPFLI~001")'.동일한 테이블에서 여러 개의 Secondary Index를 구분하기 위해 세 글자의 인덱스 식별자(Index Identifier)를 사용합니다.
테이블에 Secondary Index 설정하기 위해서는 다음과 같은 단계를 밟아나가면 됩니다.
1. Dicionary : Change Table에서 "Indexes" 버튼을 누릅니다.
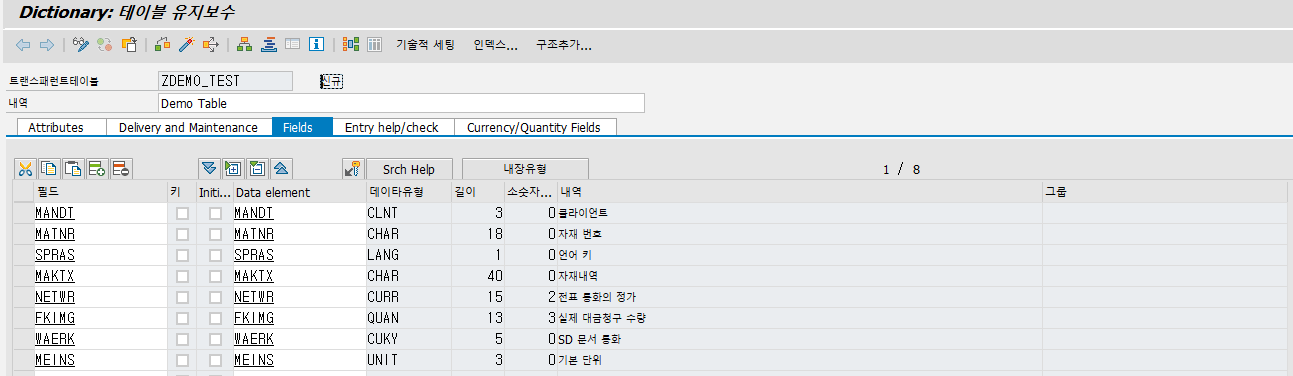
2. 시스템은 데이터베이스 테이블에 생성된 모든 Secondary Index를 표시하는 창을 엽니다. Secondary Index가 정의되지 않은 경우, 이 창은 빈 목록을 보여줍니다. "Create" 버튼을 클릭하고 아래 그림에 표시된 대로 드롭다운 메뉴에서 "Create Index"를 선택하세요.
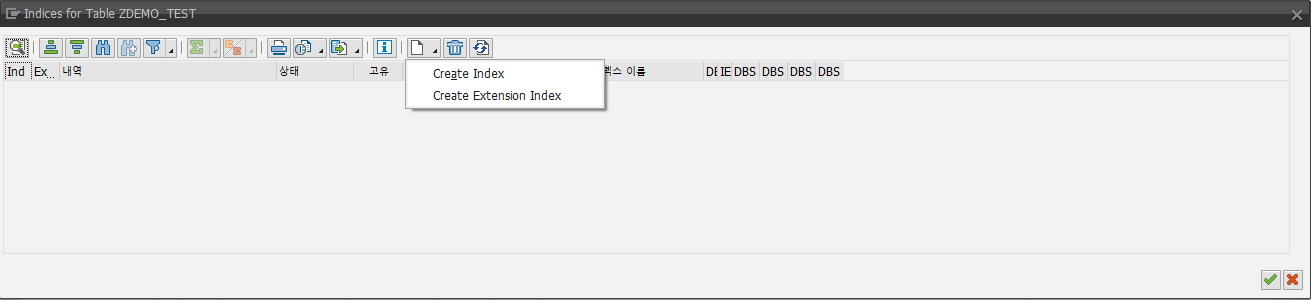
3. 누르고 나면 "Create Index" 다이얼로그 박스가 나타나며, Index Name를 입력하고 Continue 버튼을 누르면 됩니다.

4. Dictionary : Change Index 화면에서(아래 그림과 같은), 의미있는 Short Description을 입력하여야합니다. 이 화면에서, Unique Index를 만들지 Nonunique index를 선택할 수 있습니다. 인덱스 필드의 값이 행을 고유하게 식별하는 경우 (즉, Primary Key 필드의 값 조합이 테이블에서 한 번 이상 존재하지 않아야 함) "Unique Index"를 선택합니다. 그렇지 않은 경우 "Nonunique index"를 선택합니다. "Nonunique index"를 선택하면 인덱스를 모든 데이터베이스 시스템에 생성할지 (Index on all databases systems), 선택한 데이터베이스 시스템에 생성할지 또는 데이터베이스에서 전혀 생성하지 않을지 (No database index)도 선택할 수 있습니다.

5. "Table Fields" 버튼을 사용하여 인덱스의 필드를 선택하세요. 선택한 필드의 순서는 매우 중요합니다. 테이블을 쿼리할 때, 인덱스는 SELECT 문의 WHERE 절과 동일한 순서로 지정되거나 SQL 옵티마이저 힌트가 제공된 경우에만 사용됩니다 (Oracle과 같은 일부 데이터베이스 시스템의 경우).
6. 필드를 선택한 후에는 인덱스를 활성화하세요. 이제 해당 테이블에 Secondary Index가 생성되었습니다.
추가적인 Secondary Index를 생성하는 것은 시스템 성능에 부작용을 일으킬 수 있습니다. 너무 많은 인덱스를 생성하거나 공통 필드가 너무 많은 인덱스를 생성하는 것은 옵티마이저가 가장 선택적인 인덱스를 선택하기 어렵게 만들 수 있으므로 좋은 아이디어가 아닙니다.
'ABAP 프로그래밍 개념 > ABAP Data Dictioanry' 카테고리의 다른 글
| 1.4 Foreign Keys (0) | 2023.05.26 |
|---|---|
| 1.3 Table Maintenance Generator (0) | 2023.05.25 |
| 1.1 Creating a Database Table (0) | 2023.05.22 |
| 1. Database Table (0) | 2023.05.16 |
| ABAP Data Dictioanry Overview (0) | 2023.05.16 |



